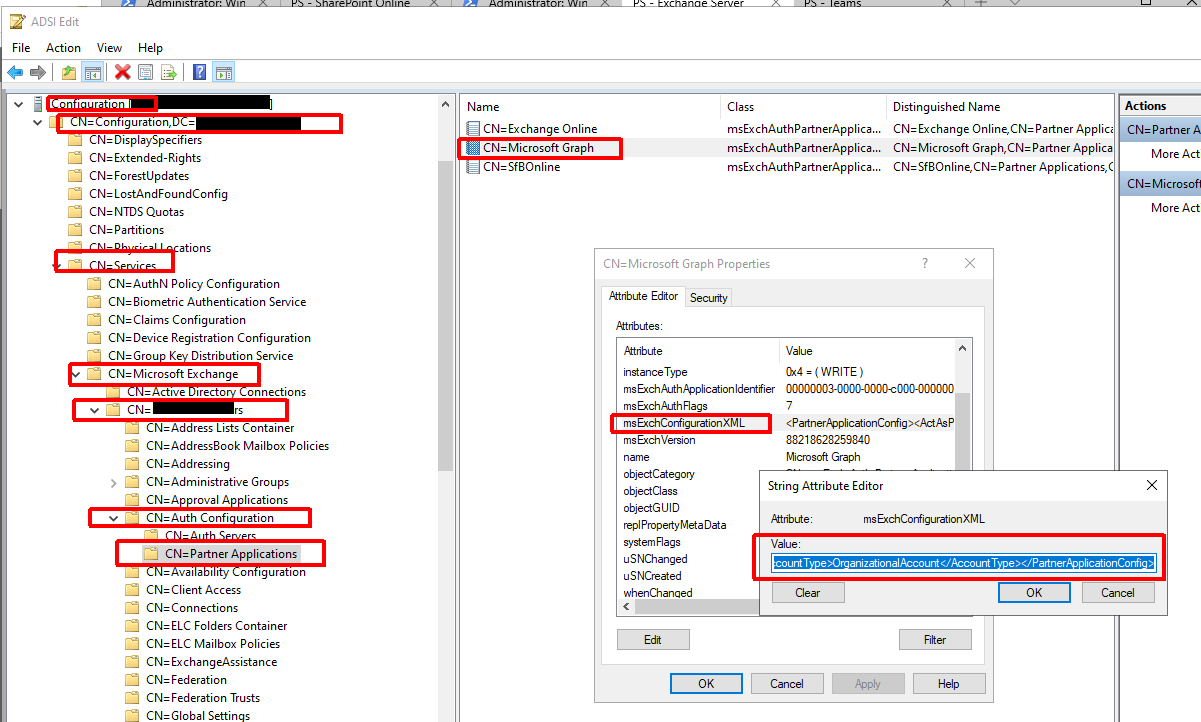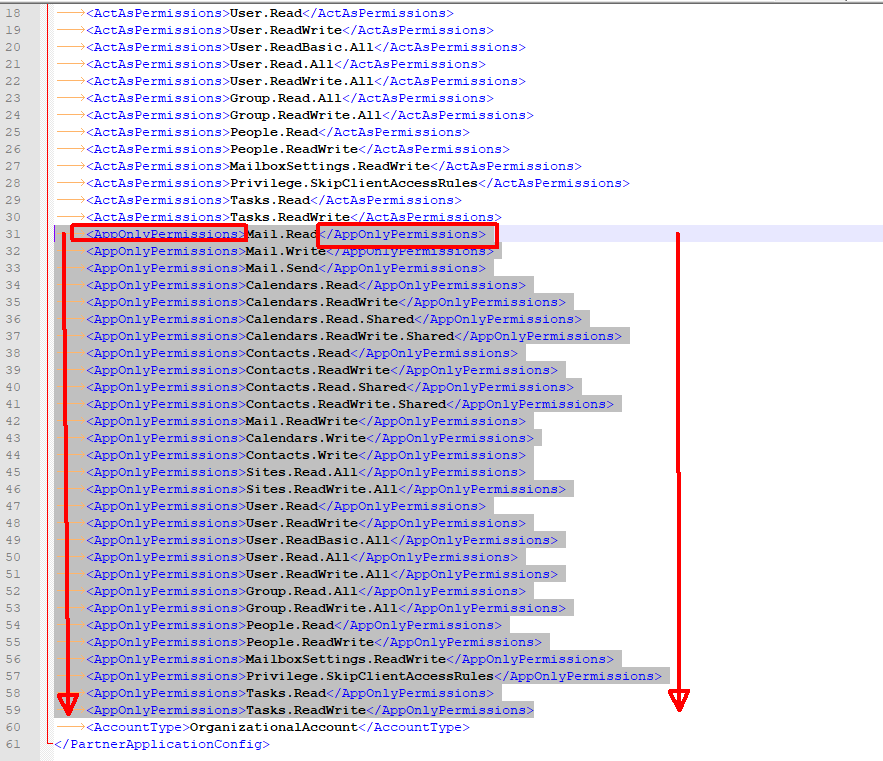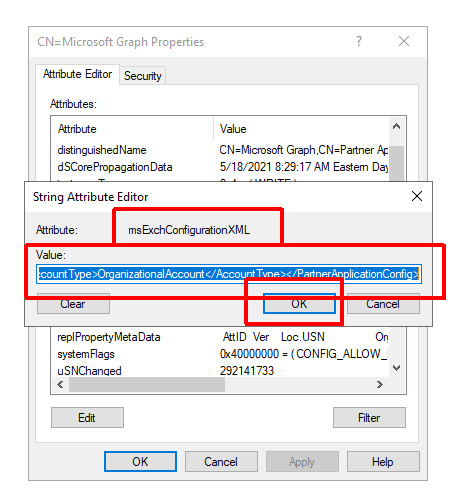
For the better part of three years we had been working to implement Information Barriers for Microsoft Teams. All throughout that time we ran into countless issues, bugs, and back-end changes forcing us to open a number of tickets with Microsoft and do multiple rounds of extensive testing before we were comfortable implementing. The day finally came when we were ready to implement. Finally one evening we had everything staged and we were ready to flip the switch later that week. To our surprise a number of unexpected changes occurred a day before flipping the switch. A large set of users were removed from teams, group chats, and meetings. There were also reports of users not being able to communicate with each other via chat/calls/meetings. Some of the users affected were not even part of either of the two IB segments that we were implementing policies for. After a little digging it became clear that IB started to go haywire sometime after we activated the IB policies (we did this as part of staging), but before running Start-InformationBarrierPoliciesApplication (this was our final step in activation). We immediately disabled both of the IB policies and ran Start-InformationBarrierPoliciesApplication to force an immediate processing of the policies. After this was done processing, all users were able to communicate again, but we were still left with all of the team/group chat/meeting removals.
I decided to start with addressing the team removals. I decided the quickest way to get a list of these was to do an Azure AD audit search since all team member removals translate to member removals of the associated M365 group. I already had experience with how IB removals show from an Azure AD perspective, so I started by running an audit search for AAD group removals and then filtered this using the three principals that could perform these IB-related removals:
Information Barrier Processor 5214069a-b412-4856-b885-c1db77635b0a Microsoft Teams Services 47ec8689-d241-46e8-adfa-c7d2144c9848 Microsoft Substrate Management 8f3d0e67-f567-4e23-8e81-2cd5ee520c4c
I then exported this to a CSV, spot checked it for any removals that seemed to not be IB-related, and ran a little PS loop to add the members back to the M365 groups:
$RemovalList = Import-Csv -Path "C:\Temp\TeamsUserReadds.csv"
ForEach ($Removal in $RemovalList) {
Add-AzureADGroupMember -ObjectId $Removal.GroupId -RefObjectId $Removal.UserId
}Now for the group chat/meetings removals; these unfortunately were not going to be easy. I started digging into how I would even detect these removals. I first tried M365 audit logs, but the IB-initiated removals did not show in any audit logs. The only place I knew of where you could see a removal was in the chat itself. Whenever a user is added or removed from a group chat/meeting there is an event message generated in the chat. I started digging into the Teams Graph APIs for ways to query these events. Eventually I wrote a pair of scripts to deal with these removals. The first script is GetGroupChatRemovals.ps1. This script crawls through all group chats (and optionally meetings) for a specified set of users over a specified date/time range for removals and creates a CSV of each unique removal. We were able to produce a set of users to scan against because every removal could be traced back to group chat/meeting where there was at least one member who was in one of the IB segments. Sometimes the user who was removed was not in either IB segment, but that didn’t matter because the script would be scanning the whole group chat/meeting for all removals. Since we knew the approximate start and end times of the removals, we had a fairly tight window of ~15 hours to scan. There were multiple challenges with the API, one of them being how it sorts chats when you request them and the inability to properly filter on the last event. I had to make the script walk backwards through chats until it was outside of the specified date/time range. After that list was created it would go through each individual message searching for the deleted system-generated member removed messages. Meetings were even worse. Not only are there many meetings, but for some reason meetings were not being returned in an order based on last event. Because of this you would have to just go through all meetings. For this reason I made scanning meetings optional. This is how the script is executed (I recommend using dot sourcing so you are able to retrieve the output variables after execution in case of a failure or issue):
."C:\Temp\GetGroupChatRemovals.ps1" -CsvPath 'C:\Temp\IBUsers.csv' -TenantId 'aa10484c-ea8b-4d62-a130-54b306384fcc' -AppId '9f3d6a8e-4e1f-436b-9972-a6918e07dbcb' -AppSecret '*PqbUTk,#d;&gK:c@[]4tRHE^TCQ<ZDQ8-NW6Q&9' -StartDateTimeString '2022-12-01T00:00:00.000Z' -EndDateTimeString '2022-12-01T15:00:00.000Z' -OutputCsvPath 'C:\Temp\ChatRemovalsOutput.csv' -ErrorTxtPath 'C:\Temp\ErrorUserUPNs.txt'The parameters are as follows:
- CsvPath – A path for a CSV containing all UPNs you are scanning (this will scan for any removals in group chats/meetings that the user was part of)
- TenantId – Your tenant ID
- AppId – Your app ID. (You will need to create an app registration with the following permissions: Chat.Read.All, ChatMember.ReadWrite.All. You will also need to request access to the Teams Protected APIs to read chats as an application)
- AppSecret – The secret created for your application registration
- StartDateTimeString – The start date/time in UTC ISO 8601 format
- EndDateTimeString – The end date/time in UTC ISO 8601 format
- OutputCsvPath – The path to write the output CSV
- ErrorTxtPath – The path to write the output TXT of UPNs of users the script was unable to retrieve chats for
- IncludeMeetings – Include this as a switch if you want to scan meetings in addition to group chats. This is optional
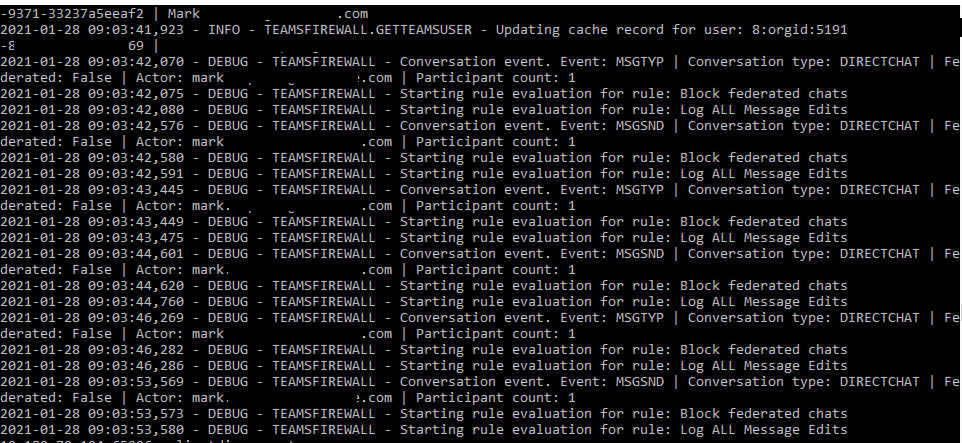
Once the script is completed you are left with output like this:

The results this script produced were surprising. IB removed many people (IB segmented and non-segmented) from many group chats. Now that we had this list we used the second script (UndoChatRemovals.ps1) to restore the memberships. This script is fairly simple and you can feed it the exact same CSV that was created from the first script. We actually decided to filter this down to a much smaller list based on the last chat activity column (by excluding stale chats). The four parameters in this script are the same as the first script. This is how the script is executed:
."C:\Temp\UndoChatRemovals.ps1" -CsvPath 'C:\Temp\ChatRemovalsOutput.csv' -TenantId 'aa10484c-ea8b-4d62-a130-54b306384fcc' -AppId '9f3d6a8e-4e1f-436b-9972-a6918e07dbcb' -AppSecret '*PqbUTk,#d;&gK:c@[]4tRHE^TCQ<ZDQ8-NW6Q&9'Once this script is completed all removed members should have been re-added. There are a few things to note. One is that there will be system messages generated in each chat for each member add event. Another is that there is no way to know if the removed member had limited visibility (added with the ability to only see beyond a certain date) or had access to the entire chat, so we have to add the user back with full visibility.
In conclusion, I will say this all could have been avoided by coupling the two IB activation steps together. Do not activate an IB policy until you are ready to run Start-InformationBarrierPoliciesApplication. The documentation does not mention that any actions happen until you complete the last step and in testing we never saw anything happen until completing the last step. For some reason IB starts to malfunction (seems to take hours for this to happen) if a policy is left active without completing the last step. When running them together it behaves as expected, lesson learned.